Inference
Once you have obtained a pipeline, either by composing rule-based components, training a model or loading a model from the disk, you can use it to make predictions on documents. This is referred to as inference. This page answers the following questions :
How do we leverage computational resources run a model on many documents?
How do we connect to various data sources to retrieve documents?
Be sure to check out the Processing multiple texts tutorial for a practical example of how to use EDS-NLP to process large datasets.
Inference on a single document
In EDS-NLP, computing the prediction on a single document is done by calling the pipeline on the document. The input can be either:
- a text string
- or a Doc object
from pathlib import Path
nlp = ...
text = "... my text ..."
doc = nlp(text)
If you're lucky enough to have a GPU, you can use it to speed up inference by moving the model to the GPU before calling the pipeline.
nlp.to("cuda") # same semantics as pytorch
doc = nlp(text)
To leverage multiple GPUs when processing multiple documents, refer to the multiprocessing backend description below.
Streams[source]
When processing multiple documents, we can optimize the inference by parallelizing the computation on a single core, multiple cores and GPUs or even multiple machines.
These optimizations are enabled by performing lazy inference : the operations (e.g., reading a document, converting it to a Doc, running the different pipes of a model or writing the result somewhere) are not executed immediately but are instead scheduled in a Stream object. It can then be executed by calling the execute method, iterating over it or calling a writing method (e.g., to_pandas). In fact, data connectors like edsnlp.data.read_json return a stream, as well as the nlp.pipe method.
A stream contains :
- a
reader: the source of the data (e.g., a file, a database, a list of strings, etc.) - the list of operations to perform (
stream.ops) that contain the function / pipe, keyword arguments and context for each operation - an optional
writer: the destination of the data (e.g., a file, a database, a list of strings, etc.) - the execution
config, containing the backend to use and its configuration such as the number of workers, the batch size, etc.
All methods (map(), map_batches(), map_gpu(), map_pipeline(), set_processing()) of the stream are chainable, meaning that they return a new stream object (no in-place modification).
For instance, the following code will load a model, read a folder of JSON files, apply the model to each document and write the result in a Parquet folder, using 4 CPUs and 2 GPUs.
import edsnlp
# Load or create a model
nlp = edsnlp.load("path/to/model")
# Read some data (this is lazy, no data will be read until the end of of this snippet)
data = edsnlp.data.read_json("path/to/json_folder", converter="...")
# Apply each pipe of the model to our documents and split the data
# into batches such that each contains at most 100 000 padded words
# (padded_words = max doc size in batch * batch size)
data = data.map_pipeline(
nlp,
# optional arguments
batch_size=100_000,
batch_by="padded_words",
)
# or equivalently : data = nlp.pipe(data, batch_size=100_000, batch_by="padded_words")
# Sort the documents in chunks of 1024 documents
data = data.map_batches(
lambda batch: sorted(batch, key=lambda doc: len(doc)),
batch_size=1024,
)
data = data.map_batches(
# Apply a function to each batch of documents
lambda batch: [doc._.my_custom_attribute for doc in batch]
)
# Configure the execution
data = data.set_processing(
# 4 CPUs to parallelize rule-based pipes, IO and preprocessing
num_cpu_workers=4,
# 2 GPUs to accelerate deep-learning pipes
num_gpu_workers=2,
# Show the progress bar
show_progress=True,
)
# Write the result, this will execute the stream
data.write_parquet("path/to/output_folder", converter="...", write_in_worker=True)
Streams support a variety of operations, such as applying a function to each element of the stream, batching the elements, applying a model to the elements, etc. In each case, the operations will not be executed immediately but will be scheduled to be executed when iterating of the collection, or calling the execute(), to_*() or write_*() methods.
map()[source]
Maps a callable to the documents. It takes a callable as input and an optional dictionary of keyword arguments. The function will be applied to each element of the collection. If the callable is a generator function, each element will be yielded to the stream as is.
| PARAMETER | DESCRIPTION |
|---|---|
pipe | The callable to map to the documents.
|
kwargs | The keyword arguments to pass to the callable. DEFAULT: |
map_batches()[source]
To apply an operation to a stream in batches, you can use the map_batches() method. It takes a callable as input, an optional dictionary of keyword arguments and batching arguments.
Maps a callable to a batch of documents. The callable should take a list of inputs. The output of the callable will be flattened if it is a list or a generator, or yielded to the stream as is if it is a single output (tuple or any other type).
| PARAMETER | DESCRIPTION |
|---|---|
pipe | The callable to map to the documents.
|
kwargs | The keyword arguments to pass to the callable. DEFAULT: |
batch_size | The batch size. Can also be a batching expression like "32 docs", "1024 words", "dataset", "fragment", etc. TYPE: |
batch_by | Function to compute the batches. If set, it should take an iterable of documents and return an iterable of batches. You can also set it to "docs", "words" or "padded_words" to use predefined batching functions. Defaults to "docs". TYPE: |
map_pipeline()[source]
Maps a pipeline to the documents, i.e. adds each component of the pipeline to the stream operations. This function is called under the hood by nlp.pipe()
| PARAMETER | DESCRIPTION |
|---|---|
model | The pipeline to map to the documents. TYPE: |
batch_size | The batch size. Can also be a batching expression like "32 docs", "1024 words", "dataset", "fragment", etc. TYPE: |
batch_by | Function to compute the batches. If set, it should take an iterable of documents and return an iterable of batches. You can also set it to "docs", "words" or "padded_words" to use predefined batching functions. Defaults to "docs". TYPE: |
map_gpu()[source]
Maps a deep learning operation to a batch of documents, on a GPU worker.
| PARAMETER | DESCRIPTION |
|---|---|
prepare_batch | A callable that takes a list of documents and a device and returns a batch of tensors (or anything that can be passed to the TYPE: |
forward | A callable that takes the output of TYPE: |
postprocess | An optional callable that takes the list of documents and the output of the deep learning operation, and returns the final output. This will be called on the same CPU-bound worker that called the TYPE: |
batch_size | The batch size. Can also be a batching expression like "32 docs", "1024 words", "dataset", "fragment", etc. TYPE: |
batch_by | Function to compute the batches. If set, it should take an iterable of documents and return an iterable of batches. You can also set it to "docs", "words" or "padded_words" to use predefined batching functions. Defaults to "docs". TYPE: |
loop()[source]
Loops over the stream indefinitely.
Note that we cycle over items produced by the reader, not the items produced by the stream operations. This means that the stream operations will be applied to the same items multiple times, and may produce different results if they are non-deterministic. This also mean that calling this function will have the same effect regardless of the operations applied to the stream before calling it, ie:
stream.loop().map(...)
# is equivalent to
stream.map(...).loop()
shuffle()[source]
Shuffles the stream by accumulating the documents into batches and shuffling the batches. We try to optimize and avoid the accumulation by shuffling items directly in the reader, but if some upstream operations are not elementwise or if the reader is not compatible with the batching mode, we have to accumulate the documents into batches and shuffle the batches.
For instance, imagine a reading from list of 2 very large documents and applying an operation to split the documents into sentences. Shuffling only in the reader, then applying the split operation would not shuffle the sentences across documents and may lead to a lack of randomness when training a model. Think of this as having lumps after mixing your data. In our case, we detect that the split op is not elementwise and trigger the accumulation of sentences into batches after their generation before shuffling the batches.
| PARAMETER | DESCRIPTION |
|---|---|
batch_size | The batch size. Can also be a batching expression like "32 docs", "1024 words", "dataset", "fragment", etc. TYPE: |
batch_by | Function to compute the batches. If set, it should take an iterable of documents and return an iterable of batches. You can also set it to "docs", "words" or "padded_words" to use predefined batching functions. Defaults to "docs". TYPE: |
seed | The seed to use for shuffling. TYPE: |
shuffle_reader | Whether to shuffle the reader. Defaults to True if the reader is compatible with the batch_by mode, False otherwise. TYPE: |
Configure the execution with set_processing()[source]
You can configure how the operations performed in the stream are executed by calling its set_processing(...) method. The following options are available :
| PARAMETER | DESCRIPTION |
|---|---|
batch_size | The batch size. Can also be a batching expression like "32 docs", "1024 words", "dataset", "fragment", etc. TYPE: |
batch_by | Function to compute the batches. If set, it should take an iterable of documents and return an iterable of batches. You can also set it to "docs", "words" or "padded_words" to use predefined batching functions. Defaults to "docs". TYPE: |
num_cpu_workers | Number of CPU workers. A CPU worker handles the non deep-learning components and the preprocessing, collating and postprocessing of deep-learning components. If no GPU workers are used, the CPU workers also handle the forward call of the deep-learning components. TYPE: |
num_gpu_workers | Number of GPU workers. A GPU worker handles the forward call of the deep-learning components. Only used with "multiprocessing" backend. TYPE: |
disable_implicit_parallelism | Whether to disable OpenMP and Huggingface tokenizers implicit parallelism in multiprocessing mode. Defaults to True. TYPE: |
backend | The backend to use for parallel processing. If not set, the backend is automatically selected based on the input data and the number of workers.
TYPE: |
autocast | Whether to use automatic mixed precision (AMP) for the forward pass of the deep-learning components. If True (by default), AMP will be used with the default settings. If False, AMP will not be used. If a dtype is provided, it will be passed to the TYPE: |
show_progress | Whether to show progress bars (only applicable with "simple" and "multiprocessing" backends). TYPE: |
gpu_pipe_names | List of pipe names to accelerate on a GPUWorker, defaults to all pipes that inherit from TorchComponent. Only used with "multiprocessing" backend. Inferred from the pipeline if not set. TYPE: |
process_start_method | Whether to use "fork" or "spawn" as the start method for the multiprocessing backend. The default is "fork" on Unix systems and "spawn" on Windows.
TYPE: |
gpu_worker_devices | List of GPU devices to use for the GPU workers. Defaults to all available devices, one worker per device. Only used with "multiprocessing" backend. TYPE: |
cpu_worker_devices | List of GPU devices to use for the CPU workers. Used for debugging purposes. TYPE: |
deterministic | Whether to try and preserve the order of the documents in "multiprocessing" mode. If set to TYPE: |
Backends
The backend parameter of the set_processing supports the following values:
simple[source]
This is the default execution mode which batches the documents and processes each batch on the current process in a sequential manner.
multiprocessing[source]
If you have multiple CPU cores, and optionally multiple GPUs, we provide the multiprocessing backend that allows to run the inference on multiple processes.
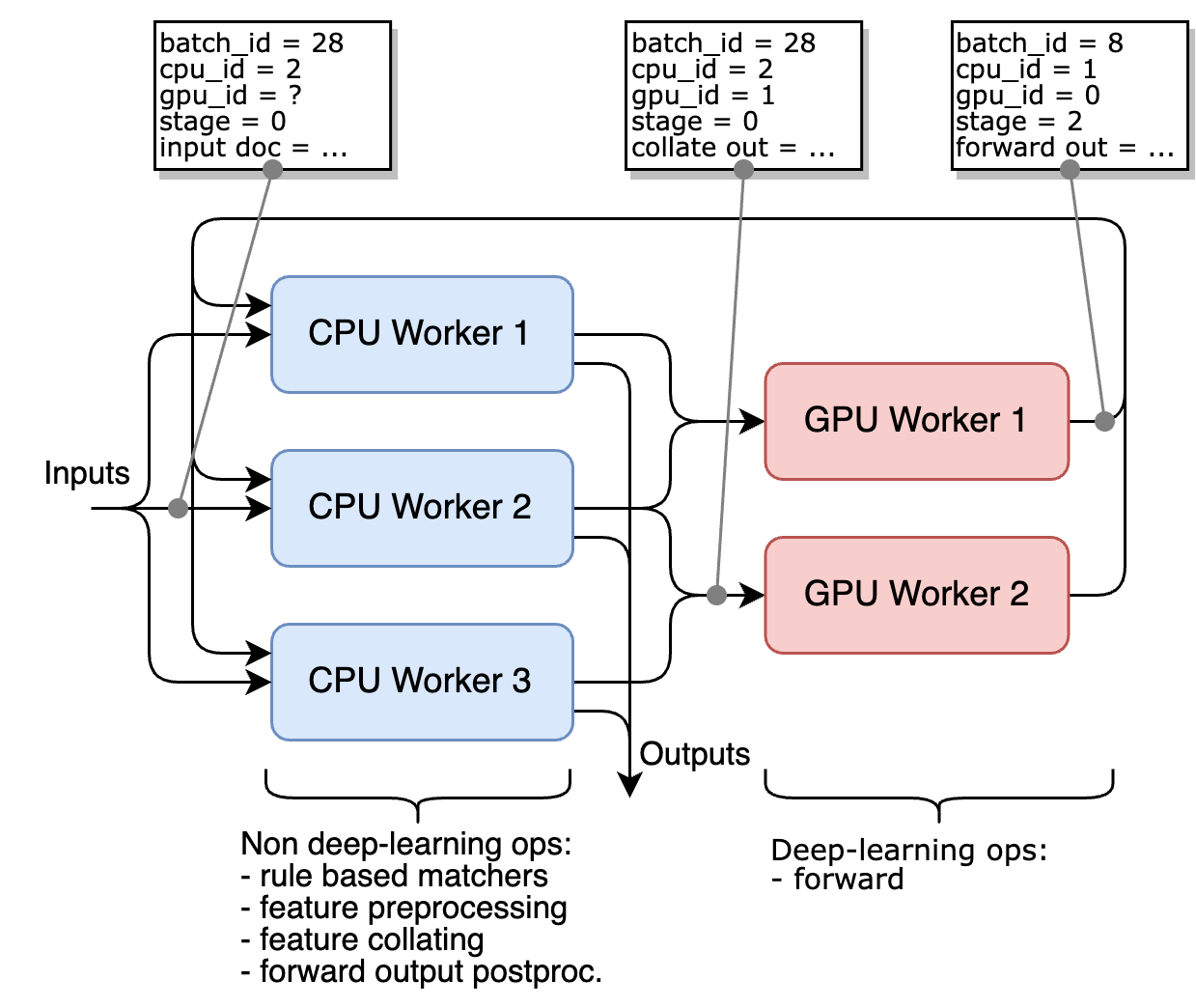
This accelerator dispatches the batches between multiple workers (data-parallelism), and distribute the computation of a given batch on one or two workers (model-parallelism):
- a
CPUWorkerwhich handles the non deep-learning components and the preprocessing, collating and postprocessing of deep-learning components - a
GPUWorkerwhich handles the forward call of the deep-learning components
If no GPU is available, no GPUWorker is started, and the CPUWorkers handle the forward call of the deep-learning components as well.
The advantage of dedicating a worker to the deep-learning components is that it allows to prepare multiple batches in parallel in multiple CPUWorker, and ensure that the GPUWorker never wait for a batch to be ready.
The overall architecture described in the following figure, for 3 CPU workers and 2 GPU workers.
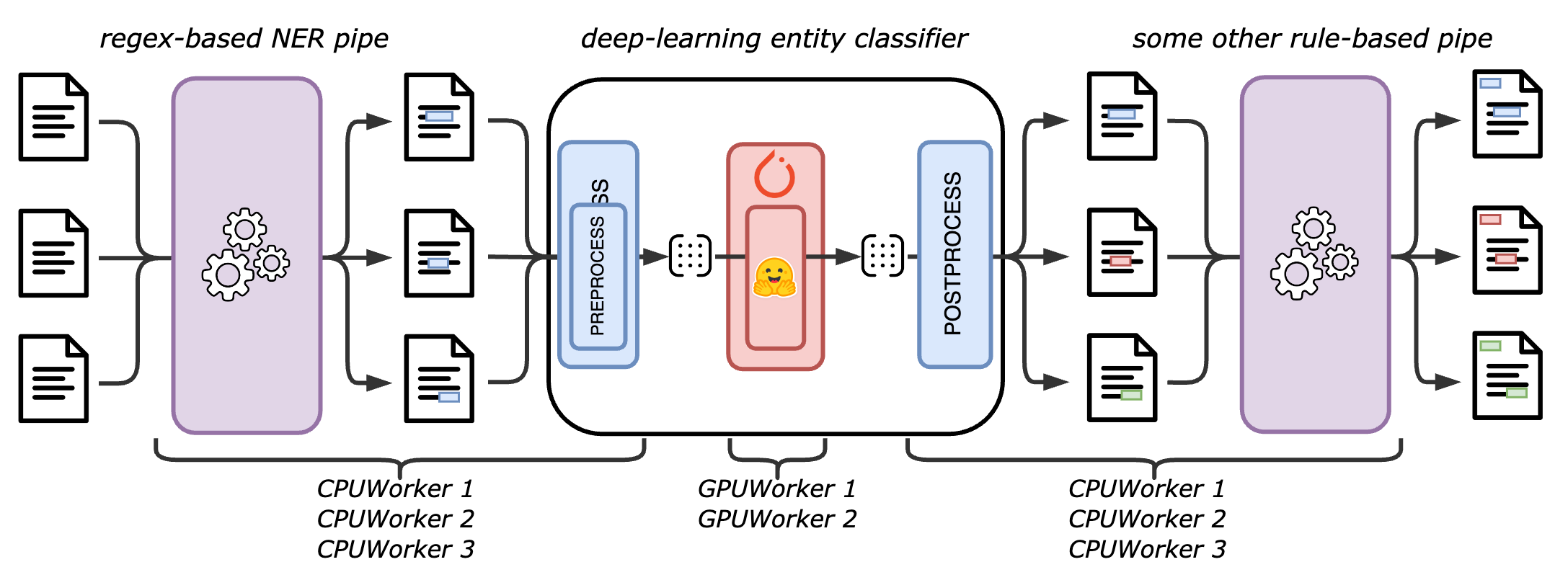
Here is how a small pipeline with rule-based components and deep-learning components is distributed between the workers:
spark[source]
This execution mode uses Spark to parallelize the processing of the documents. The documents are first stored in a Spark DataFrame (if it was not already the case) and then processed in parallel using Spark.
Beware, if the original reader was not a SparkReader (edsnlp.data.from_spark), the local docs → spark dataframe conversion might take some time, and the whole process might be slower than using the multiprocessing backend.
Batching
Many operations rely on batching, either to be more efficient or because they require a fixed-size input. The batch_size and batch_by argument of the map_batches() method allows you to specify the size of the batches and what function to use to compute the size of the batches.
# Accumulate in chunks of 1024 documents
lengths = data.map_batches(len, batch_size=1024)
# Accumulate in chunks of 100 000 words
lengths = data.map_batches(len, batch_size=100_000, batch_by="words")
# or
lengths = data.map_batches(len, batch_size="100_000 words")
We also support special values for batch_size which use "sentinels" (i.e. markers inserted in the stream) to delimit the batches.
# Accumulate every element of the input in a single batch
# which is useful when looping over the data in training
lengths = data.map_batches(len, batch_size="dataset")
# Accumulate in chunks of fragments, in the case of parquet datasets
lengths = data.map_batches(len, batch_size="fragments")
Note that these batch functions are only available under specific conditions:
- either
backend="simple"ordeterministic=True(default) ifbackend="multiprocessing", otherwise elements might be processed out of order - if every op before was elementwise (e.g.
map(),map_gpu(),map_pipeline()and no generator function), orsentinel_modewas explicitly set to"split"inmap_batches(), otherwise the sentinel are dropped by default when the user requires batching.